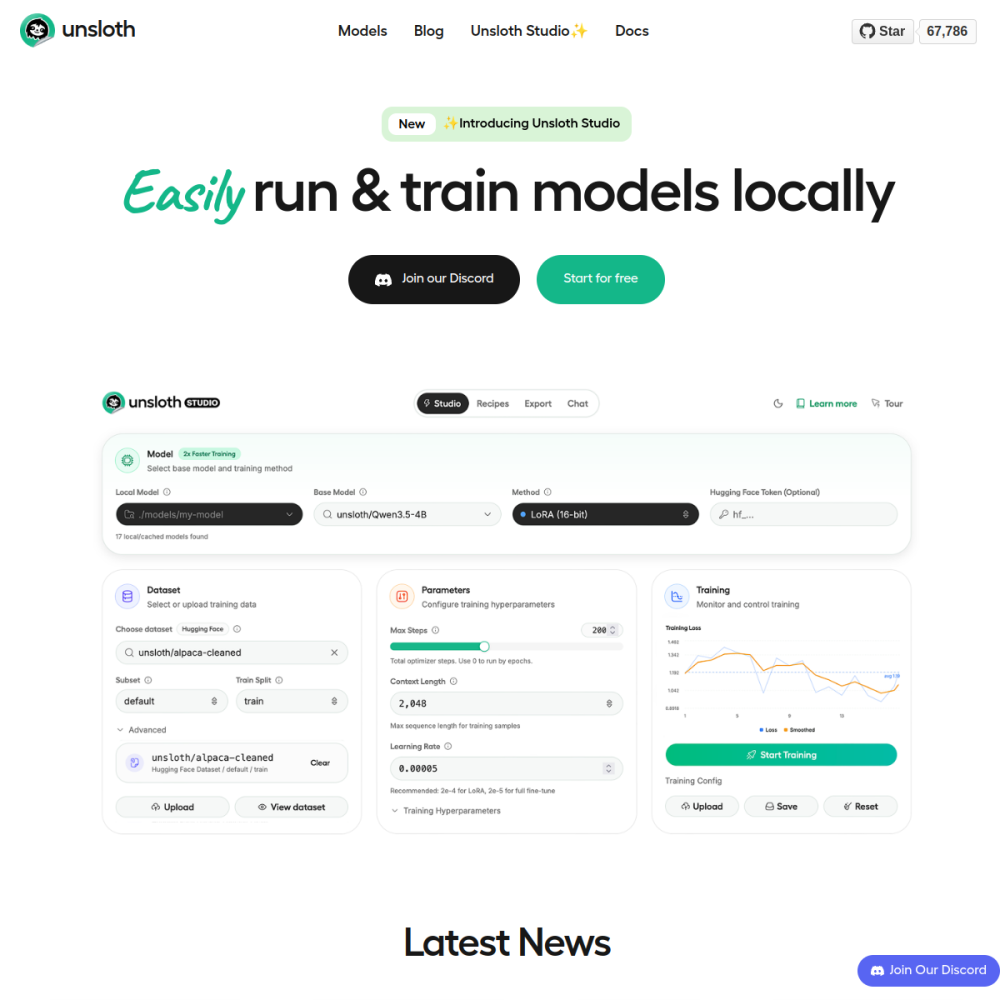
Lightning-fast LoRA training
2-5× faster than alternatives
// official site: unsloth.ai ↗
Unsloth is the fastest LLM fine-tuning library — custom Triton kernels deliver 2× the speed and 50% less VRAM than vanilla HuggingFace + PEFT. Maintained by Unsloth AI (Daniel Han, ex-Microsoft). The library of choice when budget GPU + speed matter.
Unsloth is the fastest LLM fine-tuning library — custom Triton kernels deliver 2× the speed and 50% less VRAM than vanilla HuggingFace + PEFT. Maintained by Unsloth AI (Daniel Han, ex-Microsoft). The library of choice when budget GPU + speed matter.
For solo developers and AI tinkerers fine-tuning on Colab/consumer GPUs, Unsloth is the canonical choice.
Concrete scenarios where teams pick Unsloth over the SaaS alternative.
2-5× faster than alternatives
7B QLoRA on 8 GB VRAM (vs 24 GB elsewhere)
load 4-bit base instantly (no quantize-at-load delay)
added Q4 2024
Llama, Mistral, Qwen, Phi, Gemma all covered
SFT, DPO, ORPO via TRL trainers
If your team profile matches one of these, Unsloth is a strong fit out of the box.
fine-tuning on consumer GPUs
running fine-tuning experiments on a budget
wanting fastest iteration on training experiments
running fine-tuning workshops on shared hardware
offering low-cost fine-tuning tier
When evaluating self-hosted options for this category, here are the dimensions on which Unsloth consistently lands above the alternatives.
The stack you'll plug Unsloth into — services, protocols, and adjacent apps in the BluixApps catalog.
/root/bluixapps/unsloth.txtbluixapps_ensure_nvidia_runtimeOperational guidance from running this in production — what to lock down, what surprises people.